Une IA local, en quelques minutes
La meilleure façon de faire tourner une IA en local en 2026, c'est d'installer Ollama, de télécharger un modèle comme Llama 4 Scout ou Gemma 4, et d'obtenir vos premières réponses en quelques minutes, tout sur votre propre machine, sans aucune donnée envoyée à l'extérieur. Si vous préférez une interface graphique, LM Studio vous y amène sans la moindre ligne de commande. Et si vous ne savez pas si votre machine peut tenir la charge, des outils comme canirun.ai et llmfit vous indiquent précisément quels modèles correspondent à votre configuration avant même de télécharger quoi que ce soit.
Les modèles open source ont franchi un seuil décisif. Un modèle de 14 milliards de paramètres tournant sur un GPU grand public atteint aujourd'hui le niveau de GPT-4 d'il y a deux ans. C'est pourquoi des milliers de développeurs, d'équipes et d'utilisateurs soucieux de leur vie privée pensent à migrer l'IA du cloud vers leurs propres machines.
Cet article couvre tout: comment tester votre matériel, quel runtime choisir, quels modèles open source valent votre temps en 2026, et comment passer de zéro à votre première réponse locale en quelques minutes.
L'épisode en lien avec l'article
L'IA local progresse rapidement !
En temoigne ce tweet de Clement Delangue (cofondateur et PDG d'HuggingFace) du 11 mai 2026 :
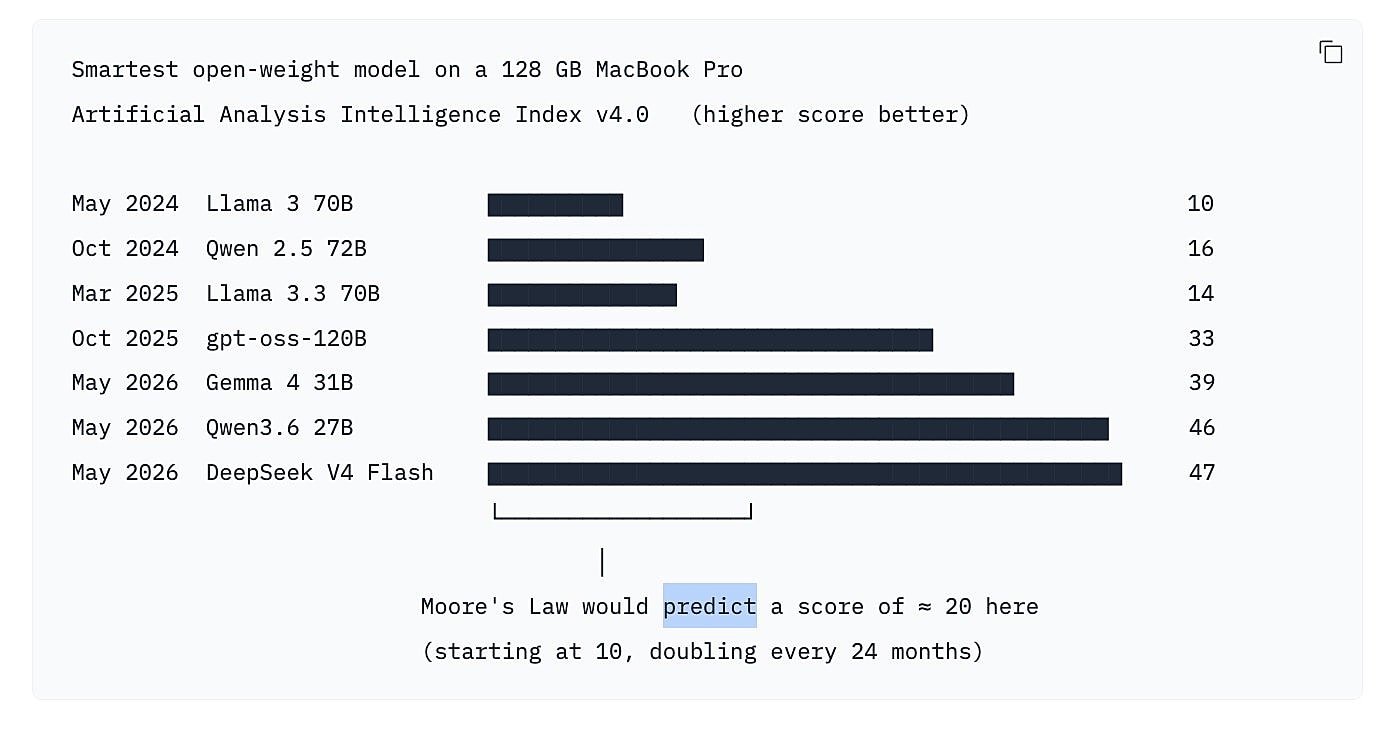
L'IA open-weight locale sur un ordinateur portable s'améliore plus du double de vitesse que la loi de Moore !
Entre mai 2024 et mai 2026, le MacBook Pro le plus cher que vous pouviez acheter est resté à 128 Go de mémoire unifiée. Le plafond matériel a à peine bougé.
Mais le modèle open-weight le plus intelligent de huggingface que vous pouviez réellement exécuter dessus est passé d'un score de 10 (Llama 3 70B) à 47 (DeepSeek V4 Flash sur le GGUF mixed-Q2 de antirez) sur l'indice Artificial Anlys Intelligence Index.
C'est 4,7× en 24 mois, soit un doublement de l'intelligence tous les 10,7 mois. La loi de Moore (nombre de transistors> ) double tous les 24 mois. L'IA open-weight locale sur un ordinateur portable s'améliore plus du double de vitesse que la loi de Moore, sur du matériel complètement inchangé.
Les points clés de l'article
- Ollama est la solution la plus rapide pour démarrer : une commande d'installation, puis
ollama run [modèle] - LM Studio propose une interface graphique complète avec un navigateur de modèles Hugging Face intégré
- Utilisez canirun.ai (navigateur, sans installation) ou llmfit (terminal, plus détaillé) pour tester votre matériel avant de télécharger
- Llama 4 Scout, Gemma 4 E4B, DeepSeek V4 Flash et Mistral Medium 3.5 sont les modèles open source les plus solides de début 2026
- 16 Go de RAM et 8 Go de VRAM GPU constituent le minimum recommandé pour une expérience fluide sur les modèles 7B
Pourquoi faire tourner une IA en local?
Le cloud est pratique. Mais il comporte des compromis que les organisations et les développeurs acceptent de moins en moins.
Chaque prompt envoyé à une API cloud transite par un serveur tiers. Pour les développeurs travaillant sur des bases de code propriétaires, les équipes juridiques traitant des documents confidentiels ou les professionnels de santé manipulant des données sensibles, c'est un problème de conformité, parfois un problème légal. Faire tourner une IA en local signifie que vos données ne quittent jamais votre machine.
Le coût est l'autre facteur. Une petite équipe qui consomme beaucoup d'appels à l'API peut facilement dépenser 200 à 500 euros par mois. Une mise à niveau GPU unique et un modèle local éliminent cet abonnement permanent.
Les dernières sorties de Llama, Qwen, Gemma, Kimi et Phi ont changé la donne pour de bon. Les modèles open source entre 7 et 14 milliards de paramètres atteignent aujourd'hui un niveau qui était réservé aux modèles frontier il y a 18 mois. La question n'est plus "est-ce assez bon?" mais "lequel correspond à mon matériel?"
Étape 1: testez votre machine avant de télécharger quoi que ce soit
L'erreur la plus courante est de télécharger un fichier modèle de 40 Go pour découvrir ensuite que votre GPU peut à peine le faire tourner. Deux outils règlent ce problème proprement.
À noter qu'avec LM Studio, dans la liste des modèles, il y a une option pour afficher ceux qui sont compatibles avec votre machine. Donc cette étape peut être évitée. Mais il est toujours intéressant de tester.
canirun.ai : le diagnostic matériel en deux minutes dans le navigateur
canirun.ai détecte vos spécifications système directement dans le navigateur via les API web standard. Il lit votre VRAM GPU, votre RAM système, le nombre de cœurs processeur et la bande passante mémoire, puis note chaque modèle de sa base de données sur une échelle allant de "Tourne parfaitement" à "Trop lourd".
La base couvre des centaines de modèles de Meta, Google, Alibaba, Microsoft et DeepSeek. Vous pouvez filtrer par type de tâche (chat, code, raisonnement, vision), licence, fournisseur et famille de modèles. Pour un premier bilan de ce que votre machine peut gérer, cela prend moins de deux minutes et ne nécessite aucune installation.
llmfit : l'analyse matérielle en profondeur avec benchmarks communautaires
Pour aller plus loin, llmfit tourne en tant qu'utilitaire terminal et vous donne un score multidimensionnel couvrant qualité, vitesse, adéquation et contexte. Il détecte les GPU NVIDIA, AMD, Intel Arc et Apple Silicon, en plus de votre RAM système et votre CPU.
Ce qui rend llmfit particulièrement utile, c'est la simulation matérielle: vous pouvez entrer une configuration cible et voir quels modèles tourneraient dessus. L'outil tire également des benchmarks communautaires montrant des tokens par seconde, temps au premier token et utilisation VRAM réels, des données bien plus fiables que les spécifications théoriques. Il s'intègre directement avec Ollama, llama.cpp, MLX et Docker Model Runner.
Configurations minimales par taille de modèle
| Taille du modèle | RAM système | VRAM GPU | Vitesse attendue |
|---|---|---|---|
| 1-3B | 8 Go | 4 Go | 30-50 tok/s |
| 7B | 16 Go | 6-8 Go | 15-25 tok/s |
| 13B | 32 Go | 12 Go | 8-15 tok/s |
| 70B (Q4) | 64 Go | 24 Go | 3-8 tok/s |
La règle d'or: la VRAM compte plus que tout le reste. Si un modèle tient en VRAM, votre GPU gère l'inférence à pleine vitesse. S'il déborde sur la RAM système, la vitesse chute de 5 à 10 fois. En cas de doute, lancez canirun.ai d'abord, puis validez avec llmfit.
Avec 16 Go de RAM, que peut-on faire tourner concrètement?
16 Go de RAM est une configuration commune. Le facteur déterminant est ce qui accompagne cette RAM, pas la RAM elle-même.
16 Go RAM, pas de GPU dédié (processeur graphique intégré)
L'inférence tourne entièrement sur le CPU. C'est possible, mais lent. Un modèle 3B tourne à 5-10 tokens/seconde : utilisable pour une réponse courte, pénible pour une conversation longue. Un 7B descend à 2-5 tok/s: chaque réponse prend 30 à 60 secondes. Le seuil d'utilisation confortable est à 10 tok/s minimum pour une conversation fluide.
Verdict: avec un GPU intégré classique, limitez-vous aux modèles 1-3B ou attendez-vous à de la patience.
16 Go RAM + GPU dédié avec 4-6 Go de VRAM
Un modèle 7B en quantisation Q4_K_M occupe environ 4,1 Go de VRAM, il tient donc dans un GPU de 6 Go. Résultat: 15 à 25 tok/s, ce qui est confortable pour une conversation. Avec 4 Go de VRAM, le modèle déborde partiellement sur la RAM système et la vitesse chute à 5-10 tok/s.
Verdict: un GPU 6 Go permet de faire tourner un modèle 7B utilisable. C'est le minimum recommandé pour une expérience acceptable.
16 Go RAM + GPU avec 8 Go de VRAM
Confortable sur les modèles 7B (25-35 tok/s), avec de la marge pour expérimenter. Les modèles 13B passent en quantisation agressive (Q3), mais la qualité baisse.
Verdict: configuration solide pour commencer. Un 7B comme Gemma 4 E4B ou Mistral Small 3 tourne sans contrainte.
Cas particulier: Apple Silicon (M1/M2/M3/M..) avec 16 Go de mémoire unifiée
Sur Apple Silicon, la RAM et la VRAM partagent le même pool. Un MacBook Air M2 avec 16 Go voit ce total comme de la mémoire GPU. Cela permet de faire tourner un modèle 13B à 15-20 tok/s, et même un 27B avec quantisation poussée. C'est l'une des meilleures configurations pour l'IA locale en mobilité, sans GPU dédié séparé.
Verdict: avec un Mac Apple Silicon 16 Go, vous pouvez faire tourner des modèles 13B confortablement, bien au-delà de ce qu'offre un PC équivalent sans GPU.
Étape 2: choisir votre runtime pour faire tourner une IA en local
Le runtime est la couche logicielle qui charge un modèle et gère l'inférence. Plusieurs options solides existent en 2026, et le bon choix dépend de votre profil et de votre cas d'usage.
Ollama : le point de départ recommandé
Ollama enveloppe llama.cpp avec une interface CLI propre et expose une API REST compatible OpenAI en localhost. L'installation se fait en une seule commande sur macOS, Linux et Windows. Une fois installé, lancer un modèle est aussi simple que:
ollama run llama4
Ollama gère automatiquement le téléchargement du modèle, la détection du GPU et la sélection de la quantisation. Il embarque un registre de modèles intégré pour parcourir et télécharger des modèles par nom. Pour les développeurs, l'API compatible OpenAI signifie qu'un code existant appelant un modèle gpt peut être redirigé vers une instance Ollama locale en changeant une seule ligne : l'URL de base.
Idéal pour: développeurs, power users, toute personne intégrant un modèle local dans une application.
LM Studio : l'option graphique
LM Studio propose une interface graphique soignée pour découvrir, télécharger et faire tourner des modèles. Il se connecte au hub de modèles Hugging Face, permet de naviguer par catégorie et taille, et télécharge directement les fichiers GGUF. Un serveur API local, également compatible OpenAI, tourne en arrière-plan et est accessible à toute application capable d'appeler un endpoint HTTP.
Idéal pour: non-développeurs, membres d'équipe souhaitant évaluer rapidement plusieurs modèles, toute personne intimidée par le terminal.
llama.cpp : le contrôle maximum
llama.cpp est le moteur d'inférence C++ qui propulse à la fois Ollama et LM Studio en coulisses. L'utiliser directement vous donne le contrôle sur chaque paramètre de quantisation, stratégie d'allocation mémoire et option matérielle. Il supporte l'inférence CPU seul, les configurations multi-GPU, Metal sur Apple Silicon, ROCm sur AMD et CUDA sur NVIDIA.
La contrepartie est la complexité: pas de navigateur de modèles, pas de détection automatique du GPU. Mais pour les développeurs optimisant la latence d'inférence en production, ou les chercheurs expérimentant avec la quantisation, l'accès direct en vaut la peine.
Idéal pour: développeurs avancés, charges de travail critiques en performance, recherche et expérimentation.
Jan AI
Jan AI se positionne comme un remplacement local complet pour la pile API OpenAI. Au-delà du texte, il gère images, audio, vidéo et embeddings, tous disponibles via un endpoint local unifié. La compatibilité avec l'API Anthropic a été ajoutée en janvier 2026. Pour les équipes qui font tourner des outils internes appelant déjà l'API OpenAI, Jan AI est le chemin de migration le plus rapide vers une infrastructure entièrement locale.
Idéal pour: équipes migrant des applications existantes intégrées OpenAI vers une infrastructure locale.
Autres outils à connaître
LocallyAI permet de faire tourner des modèles sur iPhone, iPad et Mac. L'application exploite au maximum les puces Apple.
GPT4All inclut une fonctionnalité LocalDocs permettant de discuter avec vos propres fichiers (PDF, Word, dépôts de code) entièrement sur l'appareil. La version 2026 a ajouté le raisonnement sur l'appareil et les appels d'outils. C'est le meilleur choix pour les workflows RAG privés sans infrastructure supplémentaire.
vLLM est la référence en production pour les équipes qui font tourner des modèles sur infrastructure GPU à grande échelle. Son architecture PagedAttention et son batching continu supportent les déploiements multi-GPU. Pour servir un modèle à des dizaines d'utilisateurs simultanés, vLLM est le bon outil, mais nettement plus complexe à configurer qu'Ollama ou LM Studio.
Infomaniak a sorti une série d’articles pour bien utiliser vLLM : https://engineering.infomaniak.com/vllm-ultimate-guide-part-1/
Tableau comparatif
| Outil | Interface | Idéal pour | Complexité |
|---|---|---|---|
| Ollama | CLI + API | Développeurs, intégrations | Faible |
| LM Studio | Graphique | Non-développeurs, évaluation | Très faible |
| llama.cpp | CLI | Avancés, performance | Élevée |
| Jan AI | API | Migration API OpenAI | Moyenne |
| GPT4All | Graphique | Chat avec documents privés (RAG) | Faible |
| vLLM | Serveur | Production, multi-utilisateurs | Élevée |
Un workflow pratique adopté par beaucoup de développeurs: LM Studio pour la découverte et l'évaluation initiale des modèles, Ollama pour le développement et l'intégration locale, vLLM lors du passage en production.
Étape 3: choisir le bon modèle open source pour tourner en local
Le paysage des modèles a évolué significativement cette année. Plusieurs sorties entre 7 et 27 milliards de paramètres égalent ou dépassent ce qui nécessitait 70B+ de paramètres en 2024.
Note: le marché des modèles open source évolue extrêmement vite : de nouvelles sorties importantes ont lieu toutes les 4 à 8 semaines. Les recommandations ci-dessous sont à jour en mai 2026. Pour suivre l'évolution en temps réel, consultez l'Open LLM Leaderboard de Hugging Face et llm-stats.com/leaderboards : ils reflètent les benchmarks actuels des modèles disponibles localement.
Que signifie "7B", "70B", "235B"?
Le "B" signifie milliards (billion en anglais). Un modèle 70B contient 70 milliards de paramètres : des valeurs numériques apprises pendant l'entraînement qui déterminent comment le modèle traite et génère du texte. Plus il y en a, plus le modèle est capable en général. Mais plus il y en a, plus il faut de VRAM pour le charger, et plus l'inférence est lente.
La règle pratique: un modèle 7B convient au chat général sur un GPU entrée de gamme; un 14B commence à mieux traiter les tâches complexes; un 70B (quantisé) s'approche des gros modèles propriétaires mais nécessite 24 Go de VRAM minimum.
Paramètres totaux vs paramètres actifs à l'inférence (architecture MoE)
Certains modèles affichent deux chiffres: par exemple "235B-A22B" ou "109B/17B actifs". Cela désigne une architecture Mixture of Experts (MoE).
Le Mixture of Experts (MoE) est une approche d’optimisation des modèles IA qui consiste à activer uniquement certaines parties du réseau de neurones en fonction de la requête, plutôt que d’utiliser l’ensemble du modèle à chaque exécution.
Dans un modèle dense classique, tous les paramètres sont utilisés pour chaque token généré. Dans un modèle MoE, les paramètres sont regroupés en "experts" spécialisés, et pour chaque token, seule une fraction de ces experts est activée. Les autres restent fermés (inactifs) pendant ce calcul précis.
Concrètement:
- Llama 4 Scout: 109 milliards de paramètres au total, mais seulement 17B actifs à chaque inférence
- DeepSeek V4 Flash: 284 milliards au total, mais seulement 13B actifs à l'inférence
Cela a deux conséquences distinctes sur votre machine. La vitesse d'inférence (tokens par seconde) correspond aux paramètres actifs : un modèle MoE avec 13B actifs génère des tokens aussi vite qu'un modèle dense 13B. En revanche, la mémoire nécessaire pour charger le modèle correspond aux paramètres totaux : tous les experts doivent rester en mémoire (VRAM ou RAM), même inactifs. Un DeepSeek V4 Flash à 284B nécessite ainsi environ 160 Go de mémoire totale pour charger l'ensemble des poids, malgré sa rapidité à l'inférence.
Quantization
La quantization est une technique qui vise à réduire la précision numérique des nombres flottants utilisés comme paramètres des réseaux de neurones profonds qui composent les LLM, afin de diminuer leur empreinte en mémoire GPU. Concrètement, les paramètres encodés en 32 ou 64 bits sont convertis vers des formats plus légers (FP16, BF16, INT8 ou INT4), ce qui permet de diviser par environ 3 la taille du modèle tout en limitant la perte de performance. On distingue le Quantization-Aware Training (QAT), appliqué pendant l'entraînement, et le Post-Training Quantization (PTQ), réalisé après entraînement et plus facile à mettre en œuvre, avec des méthodes populaires comme GPTQ ou NF4. Au final, la quantization réduit la consommation mémoire et énergétique ainsi que les temps d'inférence, au prix d'un compromis à trouver avec la précision du modèle.
Meilleur modèle généraliste: Llama 4 Scout (Meta)
Llama 4 Scout (64GB) est un modèle Mixture-of-Experts de 109 milliards de paramètres total avec seulement 17B actifs pendant l'inférence. Sa fenêtre de contexte est de 10 millions de tokens et il est nativement multimodal (texte et images).
VRAM requise: Scout en quantisation 1.78-bit tient sur un GPU de 24 Go (RTX 4090) à environ 20 tokens/seconde. En INT4 standard, il faut 48-55 Go (deux H100 ou une H100 80 Go). Pour la plupart des usages grand public, Scout reste un modèle orienté infrastructure. Les variantes Q4 sur GPU 24 Go existent mais restent limitées en débit.
Licence: Meta Llama 4 Community License (usage commercial autorisé avec attribution).
Meilleur pour les ordinateurs portables et l'edge: Gemma 4 E4B (Google)
Gemma 4 E4B (9.6GB) est conçu pour les appareils légers. Il est nativement multimodal (texte, image, vidéo, audio) et tourne sur MacBook Apple Silicon, machines avec graphiques intégrés et appareils de type Raspberry Pi.
VRAM requise: 5 Go minimum (Q4_K_M); 6-8 Go recommandés pour un usage confortable au quotidien. Une GPU de 8 Go (RTX 3070, etc.) offre une expérience fluide.
Licence: Apache 2.0.
Un article de Yoandev qui teste le modèle Gemma 4 sur du code https://yoandev.co/gemma4-opencode-benchmark
Meilleur pour le code haute performance: DeepSeek V4 Flash (284B/13B actifs)
DeepSeek V4 Flash uniquement en preview et en ollama cloud pour le moment, sorti en avril 2026, obtient 91,6 sur LiveCodeBench et 94,8 sur HMMT 2026. C'est un modèle MoE de 284 milliards de paramètres avec seulement 13B actifs à l'inférence. Il supporte une fenêtre de contexte d'1 million de tokens et propose trois modes de raisonnement : réponse directe, réflexion standard, et raisonnement approfondi.
Important: DeepSeek V4 Flash est disponible sur Ollama via un endpoint cloud (deepseek-v4-flash:cloud). Contrairement aux autres modèles de cette liste, il n'est pas téléchargeable localement : les appels sont routés vers l'API DeepSeek. À utiliser pour des capacités d'agents avancées via l'interface Ollama, mais pas pour un usage 100% local et hors ligne.
Pour le code sur GPU grand public (16-17 Go VRAM): Qwen3.6-27B reste la référence accessible, avec 77,2% sur SWE-bench Verified et Apache 2.0.
Licence: MIT.
Meilleur pour le raisonnement: Phi-4 Reasoning Plus (Microsoft, 14B)
Phi-4 Reasoning Plus (9,1GB) de Microsoft dépasse Llama 3.1 70B sur les benchmarks de raisonnement mathématique et de logique multi-étapes avec seulement 14 milliards de paramètres. En Q4_K_M, il nécessite environ 7,8 Go de VRAM, ce qui le rend accessible sur une RTX 3080 ou une RTX 4070.
Licence: MIT.
Généraliste haute performance: Mistral Medium 3.5 (128B)
Mistral Medium 3.5 (80GB) combine instruction-following, raisonnement et code dans un seul modèle dense de 128 milliards de paramètres. Il obtient 77,6% sur SWE-bench Verified, supporte la vision, est multilingue natif et expose des appels de fonctions natifs avec sortie JSON. Sa fenêtre de contexte est de 256K tokens.
Infrastructure requise: modèle dense de 128B, environ 70-80 Go en Q4. Nécessite plusieurs GPU ou une station de travail dédiée pour fonctionner à pleine vitesse. Disponible directement via ollama run mistral-medium-3.5.
Licence: Modified MIT (usage commercial autorisé, avec exceptions pour les entreprises dépassant un certain seuil de revenus).
Agent autonome et coding longue durée: Kimi K2.6 (Moonshot AI)
Kimi K2.6 est conçu pour les tâches de coding complexes et les workflows autonomes longue durée. Il peut orchestrer jusqu'à 300 sous-agents exécutant 4 000 étapes coordonnées, supporte la vision (texte et image) et dispose d'une fenêtre de 256K tokens.
Important: Kimi K2.6 est disponible sur Ollama via un endpoint cloud (kimi-k2.6:cloud). Contrairement aux autres modèles de cette liste, il n'est pas téléchargeable localement : les appels sont routés vers l'API Moonshot AI. À utiliser pour des capacités d'agents avancées via l'interface Ollama, mais pas pour un usage 100% local et hors ligne.
Licence: open-source via API Moonshot AI.
Tableau de sélection rapide
| Besoin | Modèle | Mémoire requise | Licence |
|---|---|---|---|
| Laptop / edge | Gemma 4 E4B | 5-8 Go VRAM | Apache 2.0 |
| Raisonnement accessible | Phi-4 Reasoning Plus | ~8 Go VRAM | MIT |
| Code accessible (GPU 16 Go) | Qwen3.6-27B | 16-17 Go VRAM | Apache 2.0 |
| Chat généraliste (infra) | Llama 4 Scout | 24 Go VRAM (1.78-bit) | Community |
| Code haute performanc (cloud Ollama) e | DeepSeek V4 Flash | API cloud | MIT |
| Généraliste + vision (serveur) | Mistral Medium 3.5 | ~80 Go (multi-GPU) | Modified MIT |
| Agent autonome (cloud Ollama) | Kimi K2.6 | API cloud | Open-source |
Étape 4: votre première IA locale en pratique
1. Testez votre matériel : ouvrez canirun.ai dans un navigateur. Notez quels modèles obtiennent la note "Tourne parfaitement" ou "Tourne bien". Pour plus de détails, installez llmfit et lancez-le depuis un terminal.
2. Installez Ollama : téléchargez l'installeur sur ollama.com. Sur macOS, il tourne en tant qu'application dans la barre de menu. Sur Linux, une seule commande curl gère l'installation:
curl -fsSL https://ollama.com/install.sh | sh
3. Téléchargez et lancez votre premier modèle selon votre matériel :
# Ordinateur portable sans GPU dédié (< 8 Go VRAM)
ollama run gemma4:e4b
# GPU milieu de gamme (8-12 Go VRAM) - usage général
ollama run mistral-small3
# GPU puissant (16-17 Go VRAM) - code
ollama run qwen3.6:27b
# GPU haut de gamme (24 Go VRAM, quantisation agressive) - généraliste
ollama run llama4:scout
Le premier lancement télécharge le modèle (2 à 80 Go selon le modèle). Les lancements suivants sont instantanés.
4. Connectez une interface : si vous voulez une interface de chat plutôt qu'un terminal, Open WebUI est l'option la plus populaire. Il se connecte automatiquement à votre instance Ollama locale et est disponible en application desktop native (sans Docker). LM Studio se connecte également à Ollama comme backend.
5. Benchmarkez votre configuration : installez llmfit pour voir vos tokens par seconde réels et identifier si un niveau de quantisation différent améliorerait les performances sur votre matériel spécifique.
Conclusion
Faire tourner une IA en local n'est plus un projet de week-end réservé aux passionnés de matériel. En 2026, un GPU milieu de gamme et quelques minutes de configuration suffisent à disposer d'un modèle de langage capable, privé et sans abonnement sur votre propre machine.
Le chemin pratique est simple: testez votre machine avec canirun.ai ou llmfit, installez Ollama ou LM Studio selon votre niveau de confort avec la ligne de commande, et choisissez un modèle adapté à votre VRAM. Pour la plupart des configurations, cela signifie Gemma 4 E4B (ordinateurs portables, 5-8 Go VRAM), Mistral Small 3 (usage général, 8-12 Go), ou Qwen3.6-27B (code, 16-17 Go). Pour les équipes avec infrastructure, DeepSeek V4 Flash et Mistral Medium 3.5 représentent l'état de l'art en mai 2026.
Le marché évolue à un rythme inhabituel : de nouveaux modèles importants sortent toutes les 4 à 8 semaines. L'Open LLM Leaderboard de Hugging Face, llm-stats.com/leaderboards et Chatbot Arena restent les références pour suivre ce qui change.